



If you heard many times the words BERT, Tranformers, Attention Head… and you still don’t really know what’s behind, here is the perfect summary.
If you wonder why we use such techniques, please read this blogpost about why BERT works better than Word2vec and LSTM.
What is BERT
BERT is a deep learning model, created by Google. It’s a statistical way to understand the language. It is a pre-trained model with many applications such as sentiment analysis, or question answering.
Why Pre-trained language models

When Google created a new network architecture in 2017 (see the famous Attention Is All You Need paper), that was a big step forward in NLP. They called this network architecture Transformer. To compare with previous architecture, understand this: there’s no more recurrence, no more “memorize the past words of a sentence” for putting a context around a word.
From this new architecture, Google released the first pre-trained model BERT which broke many record. It is so popular because usable for many NLP tasks, with very few additional training : “BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks”
What is the idea to create BERT ?
Using mask modeling :
- you download 100Gb of text (and tokenize it using WordPiece Tokenisation, see Tokenization)
- hide some words (well… the “tokens”)
- ask your model to guess for hidden words.
So basically that’s it. You play Hide and seek with your deep learning architecture, and ath the end, it has a good understanding of your language. A statistic understanding of course, but still quite good.
For instance, I tested the BERT model asking it to find what could fit the best in the sentence Paris is the ????? of France.
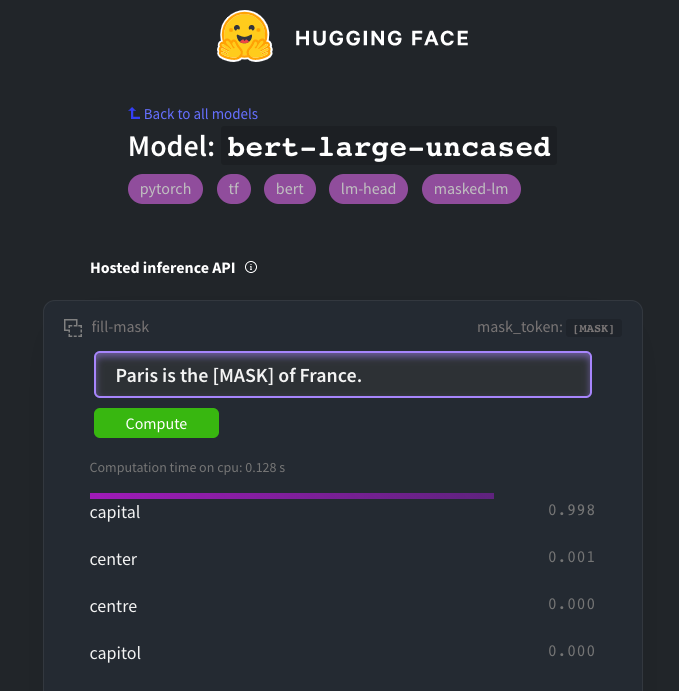
Thanks @HuggingFace for letting this BERT inference possible.
Pretty good right ? You may wonder how he can be 99% sure that capital would be a good fit. Well, it’s quite simple : the model has read a big part of the internet. And many times, it has read about Paris being the French capital. It may have even read this exact sentence.
So let’s try with something it has never seen : I make up a name, and will ask BERT to tell me more about this imaginary person.
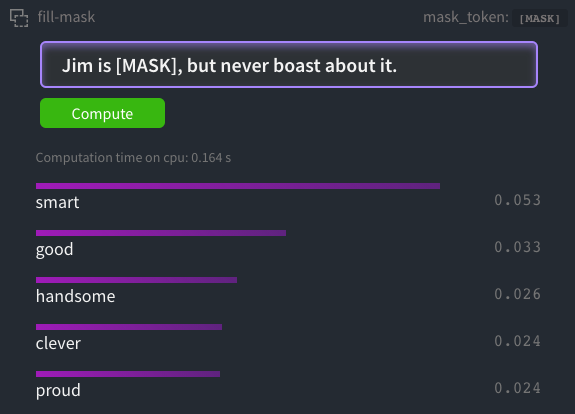
Note that all words are adjectives : BERT knows the kind of expected words. However, he is not confident on his guesses : only 5% of confidence. BERT has many possibilities in mind, which may explain this.
For the nerds, the original quote
This is from the orignial BERT paper, and is sefl-explanatory :
BERT alleviates the previously mentioned unidirectionality constraint by using a “masked language model” (MLM) pre-training objective, inspired by the Cloze task (Taylor, 1953). The masked language model randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked arXiv:1810.04805v2 [cs.CL] 24 May 2019 word based only on its context. Unlike left-to-right language model pre-training, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer. In addition to the masked language model
If you want to learn more about MLM, or how the text is actually represented before entering BERT, see this blogpost
What is the BERT architecture
-
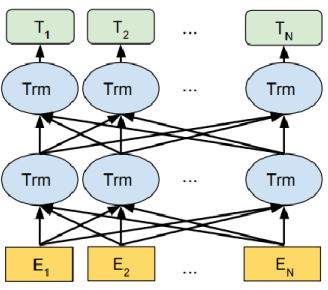
Embedding layer E: creates the embedding representation of an input word. Think of it as the word vectorisation. -
Intermediate layers, the Transformer Blocks Trm: representations of the same word. (Every layer does some multi-headed attention computation on the word representation of the previous layer to create a new intermediate representation) -
Final output T
In the origianl paper, there were 2 similar architecture
- base – 12 layers, 12 attention heads, and 110 million parameters
- Large – 24 layers, 16 attention heads and, 340 million parameters
For information, training base BERT on 4 cloud TPUs took 4 days.
Tokenisation
let’s say, we have this sentence :
My dog is cute. He likes playing.
After the tokenization, this sentence turns out to be
[CLS] my dog is cute [SEP] he likes play ##ing [SEP]
You basically understand that tokeninsation consists in removings uppercase letters, adding specific anchors instead of ponctuation, and grabbing the root meaning of words.
While BERT uses WordPiece algorithm for tokenization, some newer model use SentencePiece. The difference is whole-word masking and not sub-word masking.
Embedding
Embedding is a vectorisation. There are many algorithm for Embedding, and BERT use WordPiece embeddings.
if you read Google’s paper, you’ll see this schema :
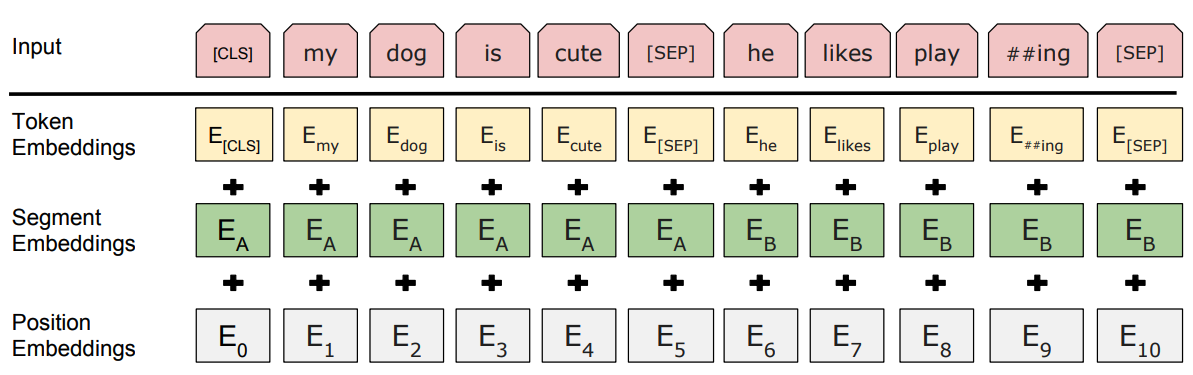 The input embeddings are the sum of the token embeddings, the segmentation embeddings and the position embeddings.
The input embeddings are the sum of the token embeddings, the segmentation embeddings and the position embeddings.
Each word gets transformed into a vector of size 512 (size that can be changed in BERT children)
You can see we have 10 columns, because the tokenized sentence has 10 tokens. In real life, the number of columns is equal to the longest sentence number of tokens. I read that for BERT, maximum number of columns was 512 - to be confirmed.
Transformer block
This part is quite long and difficult. Best sources of information are these :
- Google 2017 paper : Attention Is All You Need
- The Annotated Transformer : harvardNLP
- Google 2018 paper : BERT
- Nice illustration of transformers : jalammar
If you don’t have time for these papers, here what you need to remember.
First what we call Transformer usually reference to the model, composed as you now understand of an Embedding layer, many Tranformer blocks in the middle, and the output layer.
Fine tuning
Now that we have BERT, what do we do ?
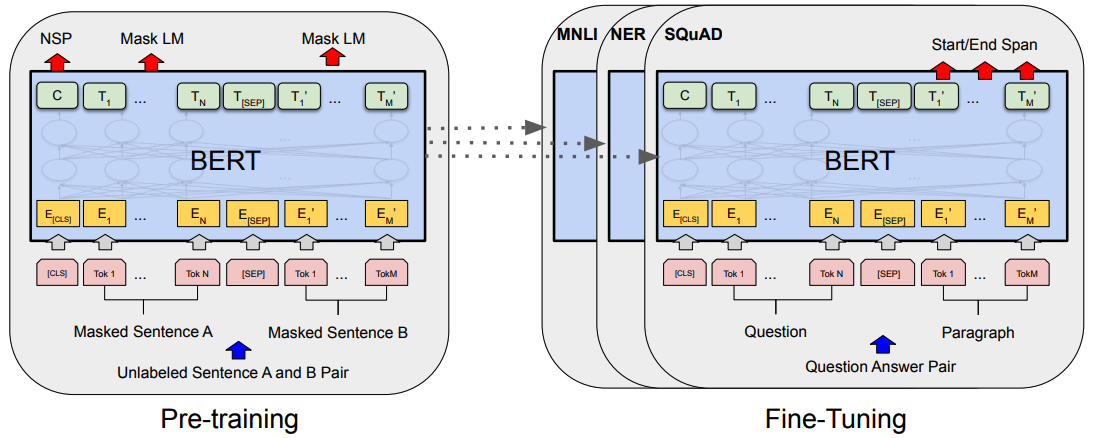
Figure 1: Overall pre-training and fine-tuning procedures for BERT. Apart from output layers, the same architectures are used in both pre-training and fine-tuning. The same pre-trained model parameters are used to initialize models for different down-stream tasks. During fine-tuning, all parameters are fine-tuned. [CLS] is a special symbol added in front of every input example, and [SEP] is a special separator token (e.g. separating questions/answers).
From this statement, we understand that BERT is sort of a big Matrix, and parameters inside this Matrix will be modified by an additional training, called the “Fine tuning” process. After BERT is fine-tuned, the output changes from “finding the word hidden by [MASK]” to a specific task like question-answering, in this case “finding the span answering the question”.
Note that every parameter from this Matrix will change, not only the one from the last transformer layer.
Reference
Fine-tuning tasks : question-answering | SQuAD
Fine-tuning tasks : sentiment-analysis | CLS
LePetit experiments : medium
Google 2017 paper : Attention Is All You Need
The Annotated Transformer : harvardNLP
Google 2018 paper : BERT
Nice illustration of transformers : jalammar
BERT faq : yashuseth blog
WordPiece Tokenisation : stackoverflow
Another Tokenisation : SentencePiece
Bias : Gender Bias in BERT
More on word embedding