



BERT = Bidirectional Encoder Representations from Transformers
What is an intent ?
Chatbots typically classify queries into specific intents in order to generate the most coherent response. So Chatbots take a question (the query), and make it a label (intent label per say). It’s called “Intent classification”, usually a multi-class classification problem, where the query is assigned one unique label.
Well… example please ?
“how much does the limousine service cost within pittsburgh” is labeled as “groundfare”
“what kind of ground transportation is available in denver” is labeled as “ground_service”
“i want to fly from boston at 838 am and arrive in Denver at 1110 in the morning” is labeled as “flight”
“show me the costs and times for flights from san francisco to atlanta” is labeled as “airfare+flight_time”
Sounds hard, isn’t it ?
We’ve seen how ambiguous intent labeling can be. Misleading words may cause multiple intents to be present in the same query. So how can we fix this ?
The answer is Attention-based learning methods (Liu and Lane, 2016; Goo et al., 2018). One type of network built with attention is called a Transformer. It applies attention mechanisms to gather information about the relevant context of a given word, and then encode that context in a rich vector that smartly represents the word.
Wait, how did we do before Transformer ?
We used LSTM : Long short-term memory. This is not abselete, it can be used with BERT as well, but this is another subject. One thing though, LSTM has poor classification results with imbalanced dataset. you can see more here
What is BERT?
BERT is basically a trained Transformer Encoder stack.
It exists in 2 version : Base and Large. BERT has 12 encoder layers (Base) & 24 (Large) while there’s 6 in the original Transformer.
Some caracteristics :
BERT encoders have larger feedforward networks (768 and 1024 nodes for B and L)
BERT encoders have and more attention heads (12 and 16 for B and L).
What did BERT read to get trained ?
English Wikipedia & BookCorpus (+10,000 books of different genres)
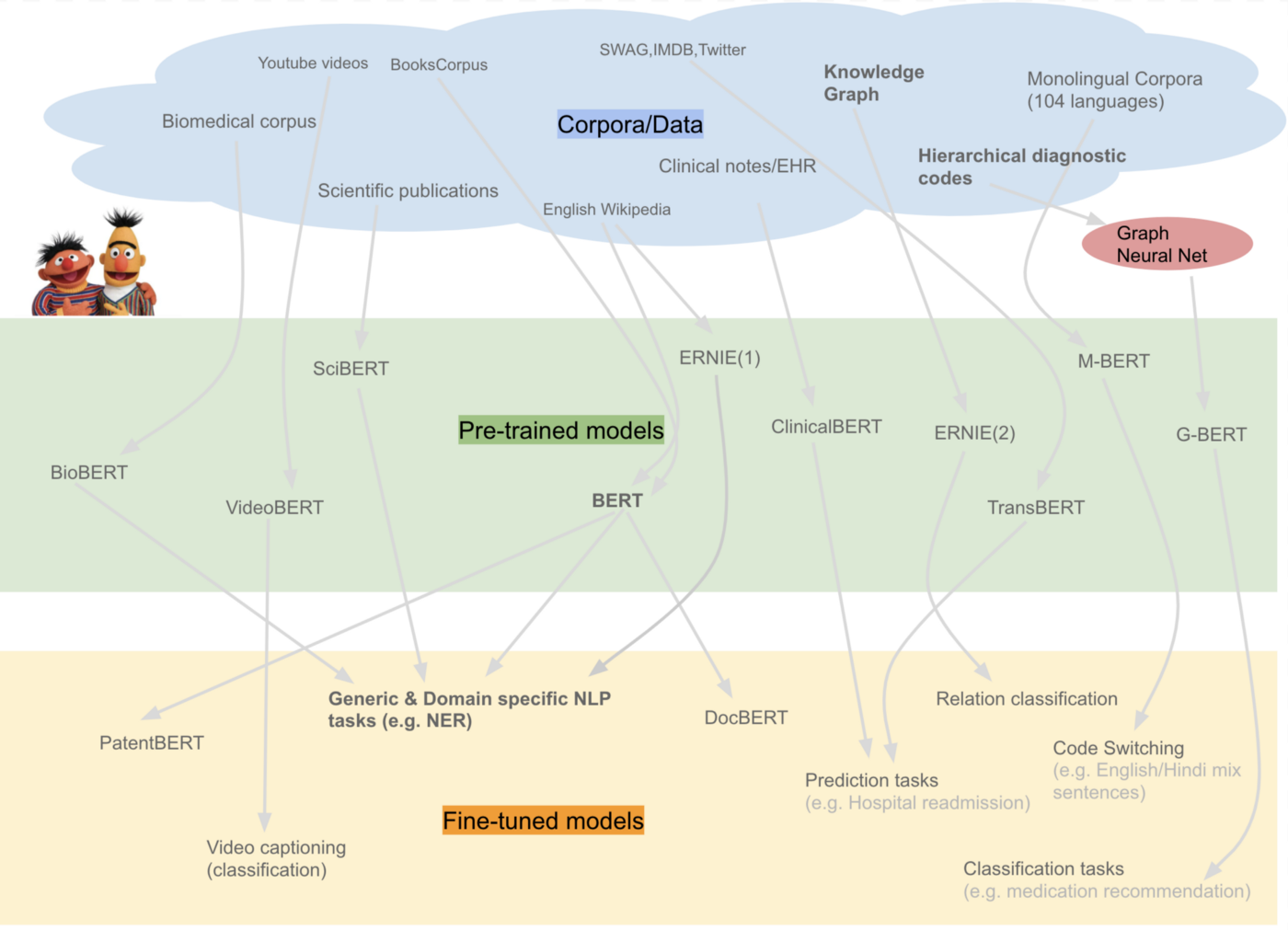
Here is a summary of BERT variants pre-trained on specialized corpora.
What happens to my query when going through BERT ?
BERT takes a sequence of words as input (your query) which keep flowing up the stack from one encoder to the next, while new sequences are coming in.
The final output for each sequence is a vector of 728 numbers (B) or 1024 (L). We will use such vectors for our intent classification problem.
What make BERT above LSTM or word2vec and other models ?
Proper language representation is key for general-purpose language understanding.
Context-free models such as word2vec or GloVe generate a single word embedding representation for each word in the vocabulary. For example, the word “bank” would have the same representation in “bank deposit” and in “riverbank”.
Contextual models instead generate a representation of each word that is based on the other words in the sentence. BERT captures these relationships in a bidirectional way.
BERT was built upon Semi-supervised Sequence Learning, Generative Pre-Training, ELMo, the OpenAI Transformer, ULMFit and the Transformer. Although these models are all unidirectional or shallowly bidirectional, BERT is fully bidirectional.
Ressources:
Blog towardsdatascience: bert-for-dummies - how to load BERT and fine-tune it for a specific task
LSTM: wikipedia
Blog towardsdatascience: fastai
Comic about Machine learning: google
{kind=link}
BERT training dataset size: arxvid