



A short explanation of TF-IDF, BM25 and their differences. And as usual, a quick list of useful references.
Intro
TFIDF (term frequency-inverse document frequency: wiki link) and BM25 (Okapi Best Matching 25: wiki link) are two methods for document searchs.
The typical use case is when you have 1000 documents, and you want to retrieve the best matching document for the search query “dog”. The solution is to look at every document, and score them with a “ranking function” that will put a high score on documents talking about dogs.
TF-IDF
The ranking formula for TF-IDF is:
Score = 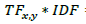 =
= 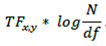
- TF x,y : number of occurrences of term x in document y (Term Frequency)
- IDF : represent the rarity of the term in the corpus (Inverse Document Frequency). with N number of documents in total (1000 in our example) and df is the number of documents that contains the term x
One assumption has to be made : the more times a document contains a term, the more likely it is to be about that term (the more relevant). In practise, it works surprinsingly well. Not always of course, but for the price of this solution, it’s very efficient.
Why the log ? => only to smooth the function for low values.
BM25
This is a TFIDF upgrade : we’ll replace TF x,y and IDF with refinements
TF tuning
- TF x,y replaced by TF / (k + TF) : this will bound the curve, and allow us to tune the contribution of TF => term saturation
- is our previous formula, we will multiply k by dl/adl. (dl = document’s length, adl = average document length). This will reduce the contribution TF in long document : long document have more chances to have more Term occurrences, while it doesn’t mean it’s more relevant. => account for document length
- Now, we tune this document length contribution with a new factor b : TF/(TF + k*(1 - b + b * dl/adl)) => importance of document length
IDF tunning
Reasearch came up with a “probabilistic IDF” to replace IDF with:
log((N - DF + .5)/(DF + .5))
This function takes a sharp drop for terms that are in most of the documents. Stopword like “and” or “or” will be discredited.
But to avoid having negative values (a word should never count less than if simply absent, with mean 0), Lucene added 1 :
So here is the formula :
log(1 + (N - DF + .5)/(DF + .5))
Conclusion
TF-IDF rewards term frequency and penalizes document frequency.
BM25 goes beyond this to account for document length and term frequency saturation.
Reference
Understanding TF-IDF and BM25 : kmwllc Blog post